Qwen3-VL 架构与训练笔记
梳理 Qwen3-VL 的模型结构、视觉特征注入、位置编码和训练流程。
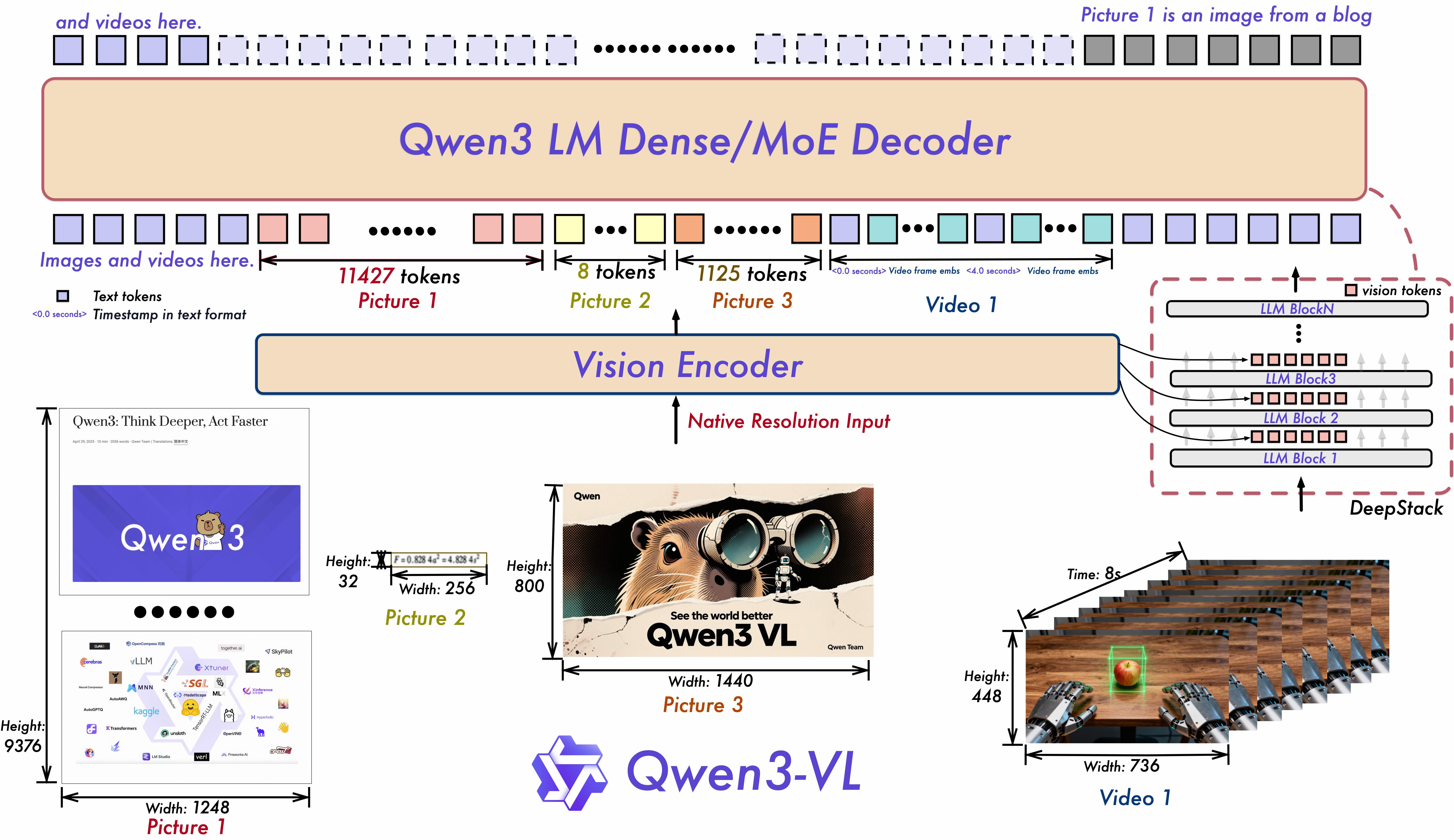
1. 模型概览
| 项目 | 内容 |
|---|---|
| 模型名称 | Qwen3-VL |
| 类型 | Vision-Language Model |
| 输入 | 文本、图像、视频 |
| 模型形态 | dense 与 MoE 两类架构 |
| 已发布尺寸 | dense: 2B/4B/8B/32B;MoE: 30B-A3B/235B-A22B |
| 主要版本 | Instruct 和 Thinking |
| 原生上下文 | 256K tokens |
| 典型能力 | OCR、文档理解、图像问答、视觉推理、视频理解、GUI/Agent 交互 |
| 开源许可 | Apache-2.0 |
关键技术改进:
- Interleaved-MRoPE
- DeepStack(Qwen3.5 中已去除)
- Text–Timestamp Alignment
2. 架构理解
架构关键词:
- 原生多模态
- 双塔架构(vision tower + language tower)
- decoder-only
说明:text model 不和 vision 一起 from scratch 训练,而是以 Qwen3 作为 text model 的 base。
其中 decoder 部分与 Qwen3/Qwen3-MoE 一致,只是会插入 DeepStack 特征。
以 Qwen3-VL-8B-Instruct 为例(非完整 config)
{
"architectures": [
"Qwen3VLForConditionalGeneration"
],
"image_token_id": 151655, // 图像占位 token
"video_token_id": 151656, // 视频占位 token
"vision_start_token_id": 151652, // 视觉块开始
"vision_end_token_id": 151653, // 视觉块结束
"text_config": {
"hidden_size": 4096, // 文本主干维度
"num_hidden_layers": 36, // 文本 decoder 36 层
"num_attention_heads": 32,
"num_key_value_heads": 8, // GQA:32 个 Q 头共享 8 组 KV
"max_position_embeddings": 262144, // 256K 上下文
"rope_scaling": {
"mrope_interleaved": true, // 用 interleaved M-RoPE
"mrope_section": [24, 20, 20] // T / H / W 三轴 rotary 分配
},
"rope_theta": 5000000, // 长上下文 RoPE 基数
"use_cache": true // 增量生成时启用 KV cache
},
"vision_config": {
"depth": 27, // 视觉塔 27 层
"hidden_size": 1152, // 视觉内部维度
"out_hidden_size": 4096, // 投影到文本维度
"patch_size": 16, // 空间 16x16 patch
"temporal_patch_size": 2, // 时间 2 帧 patch
"spatial_merge_size": 2, // 进入 LLM 前做 2x2 merge,压缩视觉 token
"deepstack_visual_indexes": [8, 16, 24] // 从中间层抽 DeepStack 特征
}
}2.1 Interleaved-MRoPE
普通文本模型只需要关心 token 在一维序列里的位置;多模态模型还要理解图像的宽、高,以及视频中的时间顺序。
这关系到:
- 多图输入时模型是否能区分不同图片
- 视频理解时模型是否能维持事件顺序
- 长上下文里模型是否能稳定引用前面的视觉信息
原有的 MRoPE 已经可以实现多模态的 position embedding,但是这里提出了 Interleaved-MRoPE。
布局从 MRoPE 传统的 [TTT HHH WWW] → [THW THW THW]。
直觉:传统布局里,T/H/W 各自占据 RoPE 的高中低频率区间,丧失了一部分频率设计的信息,引入了不必要的 bias,让 T/H/W 对位置的敏感性天然不同。Interleave 让各个维度平等使用 position 频率。
def apply_interleaved_mrope(self, freqs, mrope_section):
"""Apply interleaved MRoPE to 3D rotary embeddings.
Reorganizes frequency layout from chunked [TTT...HHH...WWW] to
interleaved [THWTHWTHW...TT], preserving frequency continuity.
args:
x: (3, bs, seq_len, head_dim // 2)
mrope_section: (3,)
returns:
x_t: (bs, seq_len, head_dim // 2)
"""
freqs_t = freqs[0] # just overwrite the first dimension T
for dim, offset in enumerate((1, 2), start=1): # H, W
length = mrope_section[dim] * 3
idx = slice(offset, length, 3)
freqs_t[..., idx] = freqs[dim, ..., idx]
return freqs_t2.2 DeepStack
DeepStack 的作用是融合多层 ViT 特征,而不是只依赖某一层视觉特征。直觉上,浅层特征更接近边缘、纹理、局部结构;深层特征更接近语义。把多层信息结合起来,有助于细粒度视觉理解和图文对齐。
deepstack_visual_indexes=(8,16,24)
vision encoder 额外在第 8、16、24 层额外保存视觉特征,最后注入 decoder。这里的实现是分别注入 decoder 的前 3 个 layer,注入方式:与对应的 vision token 位置做 element-wise add。
直觉:对于 vision token 进行特殊加强,在前几层强制保留/注入 vision feature,防止 decoder 只看文字进行推理(这也是现有多模态模型的一个主要难题)。
for layer_idx, decoder_layer in enumerate(self.layers):
layer_outputs = decoder_layer(...)
hidden_states = layer_outputs
if deepstack_visual_embeds is not None and layer_idx in range(len(deepstack_visual_embeds)):
hidden_states = self._deepstack_process(
hidden_states,
visual_pos_masks,
deepstack_visual_embeds[layer_idx],
)
def _deepstack_process(
self, hidden_states: torch.Tensor, visual_pos_masks: torch.Tensor, visual_embeds: torch.Tensor
):
visual_pos_masks = visual_pos_masks.to(hidden_states.device)
visual_embeds = visual_embeds.to(hidden_states.device, hidden_states.dtype)
hidden_states = hidden_states.clone()
local_this = hidden_states[visual_pos_masks, :] + visual_embeds
hidden_states[visual_pos_masks, :] = local_this
return hidden_states2.3 Text-Timestamp Alignment
视频理解不是把每一帧看成独立图片那么简单。模型需要知道事件发生在什么时候,以及文本描述和视频片段之间如何对齐。
这对两个场景很关键:
- 长视频检索:在几分钟甚至更长视频里找到事件位置
- 视频问答:回答“某个动作什么时候发生”“前后顺序是什么”
<t seconds><vision_start>...frame tokens...<vision_end>
处理流程:
- 从
video_metadata里取fps和frames_indices - 用
_calculate_timestamps(...)计算每个 temporal patch 对应的时间 - 给每个 frame chunk 前插入文本形式的
<{curr_time:.1f} seconds>时间戳 - 再拼上
<|vision_start|> ... <|vision_end|>
注意:时空压缩比 2 x 16 x 16,由于 time 的融合,实际的文字时间戳也会取两 frame 的均值。
3. 训练和能力来源
Pre-training:4 个阶段

Stage 0:Vision-Language Alignment
先做模态对齐。这一步只训练中间的 merger / projector,视觉编码器和文本 backbone 先冻结,目标是先把视觉特征稳定接到语言空间里。综述给出的设置是:约 67B tokens,数据以高质量图文描述、视觉知识、OCR 为主,序列长度 8K。
Stage 1:Multimodal Pre-Training
然后进入全参数端到端预训练。视觉编码器、merger、LLM 全部解冻,一起在大规模混合数据上训练,数据既有图文交错、grounding、VQA、STEM、视频,也保留 text-only 数据,目标是让模型在不伤文本能力的前提下获得强多模态能力。规模约 1T tokens,上下文仍是 8K。
Stage 2:Long-Context Pre-Training
第三步把上下文从 8K 拉到 32K,继续训练,重点强化长文本、长视频和跨段检索/引用能力,同时提高视频和 agent-oriented 数据占比。规模约 1T tokens。
Stage 3:Ultra-Long-Context Adaptation
最后再把上下文推到 256K,用一个更聚焦的数据集做长上下文适配,重点放在长视频和长文档。规模约 100B tokens
Post-training:3 个阶段
1)SFT
先做监督微调,激活指令跟随和多模态任务能力。这里又分两步:先在 32K 上训练,再扩到 256K,后者更聚焦长文档、长视频。thinking 和 non-thinking 的数据格式不同,thinking 版本会更强调中间推理过程。
2)Strong-to-Weak Distillation
再做强到弱蒸馏,把更强教师模型的能力迁移到更小模型。综述提到这里尤其会用大量 text-only 蒸馏来把文本/推理能力稳住。
3)RL
最后做强化学习,进一步拉高推理、工具调用、grounding 等能力。综述提到它把 RL 分成 reasoning/general 两类,并用多种 reward 信号去同时约束答案正确性、多轮推理和工具使用质量。
- Text backbone 用 Qwen3,也就是 decoder-only 文本主干;HF 代码里
Qwen3VLTextModel直接继承Qwen3Model。 - Vision encoder 用 SigLIP-2 路线,从官方预训练 checkpoint 初始化,再继续做动态分辨率训练。
- 中间靠 merger / DeepStack / interleaved MRoPE / 文本时间对齐把两边接起来,这也是论文摘要点名的三项核心架构升级。