vLLM 工程拆解:从 API Server 到 PagedAttention
基于 vLLM main 分支,按入口、配置、引擎、调度、KV cache、Worker、模型适配、Attention backend 和底层 kernel 拆解这个 LLM serving 工程。
最新
基于 vLLM main 分支,按入口、配置、引擎、调度、KV cache、Worker、模型适配、Attention backend 和底层 kernel 拆解这个 LLM serving 工程。
从 LLM serving 的角度理解 vLLM 如何通过调度、batching、KV cache 管理和执行引擎把单请求生成变成高并发在线服务。
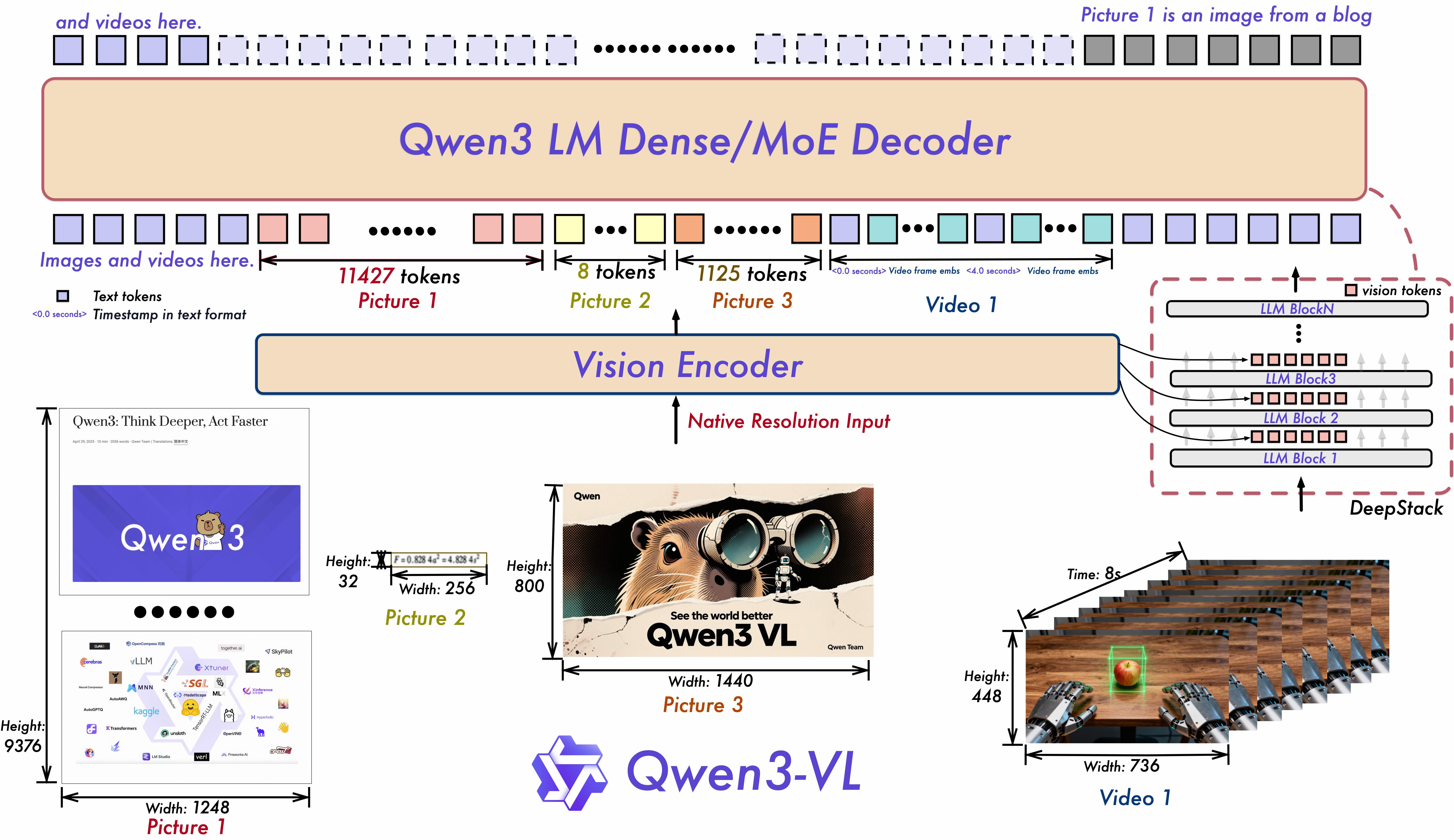
梳理 Qwen3-VL 的模型结构、视觉特征注入、位置编码和训练流程。